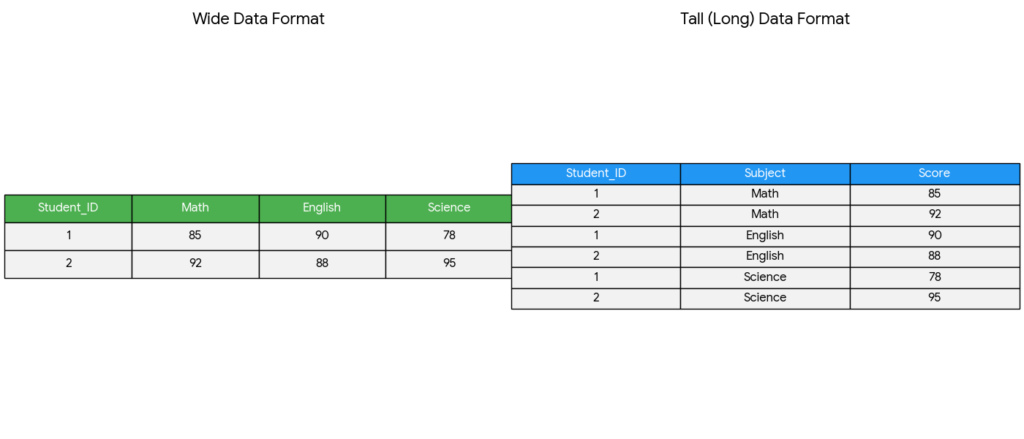
As LLMs move into research settings, social scientists face a familiar but newly urgent problem: how to incorporate a powerful new tool without surrendering methodological clarity. These systems can support parts of qualitative research in intriguing ways: summarizing interviews, generating candidate codes, comparing excerpts, and surfacing patterns across documents. But they also risk flattening ambiguity, overstating coherence, and producing interpretations that sound persuasive before they have been properly examined. We are used to asking how tools shape what we can know. Large language models now belong in that conversation. There are both practical and epistemological reasons why we should be thinking about this in the context of using LLMs responsibly in research. This is why I think we need more than fluency; We need literacy.
AI literacy vs operational fluency
One of the main ideas from our recent GCDI workshop was a simple distinction:
- Operational fluency is about using the tool smoothly and getting to “a result” quickly.
Example: you can produce a summary, a list of themes, a draft paragraph, or a chunk of code without a lot of friction.
- AI literacy is about understanding what kind of system you are interacting with, what it is optimized to do, and how it can fail.
Example: you know why a summary might omit caveats, why “themes” can sound more definitive than your data supports, and how to structure prompts so the model has to show its work.
Operational fluency tends to increase speed. AI literacy helps you keep that speed aligned with research judgment. A simple way to say it is this: operational fluency gets you to an output, AI literacy helps you decide what the output is worth.
When I explain context windows and prompting, I like a river metaphor.
Imagine a riverbed full of material. Some of it is valuable, some of it is noise, and some of it looks valuable until you test it. Your job is to extract something useful from what is available.
In an LLM interaction, the context window is the stretch of river you can access in the moment. It includes your instructions, the text you paste, the chat history, and, in some systems, the passages retrieved from a corpus. That is the material the model can condition on when it generates its response. The prompt is like choosing a tool and a technique for extraction. Panning, sluicing, dredging, and metal detection will all give you different results, even if you stand in the same spot.
One important detail keeps this metaphor honest. The model is not literally pulling “facts” out of the riverbed. It is generating new text by prediction, and the “river” is the material that shapes which continuations become likely.
This is why operational fluency alone can be misleading. Every time you get to an output quickly, it can feel like you found gold. AI literacy is what helps you test whether it is gold, fool’s gold, or just a rock.
A mental model: what happens when you prompt?
1) Tokenization: breaking the material into workable pieces
Before the system can “work” with your text, it breaks it into tokens. Tokens are not always words. They can be word pieces, punctuation, or even spaces.
In the river metaphor, you cannot pan a boulder. You need grains. Tokenization is how the system turns language into pieces small enough to handle computationally.
Why this matters: token limits shape what you can include, what gets left out, and how much context the system can use.
2) Embeddings: giving tokens measurable signatures
Next, tokens are converted into vectors, often called embeddings. This is one of the key “math about language” moves. Language becomes something that can be computed on.
In the metaphor, embeddings are like giving each grain a measurable signature. Not a perfect definition of meaning, but a numerical representation that lets the model compare, group, and relate pieces of text.
3) Attention: deciding what influences what
Transformer-style models use attention mechanisms to estimate how much each token should draw from other tokens in the context. This is one reason your wording and structure matter so much. The model is constantly reweighting what counts as relevant.
In the metaphor, attention is like controlling the flow through a sluice. You are not changing the river itself. You are changing what gets caught and what washes through.
A useful literacy note: attention is not automatically the model’s “reason.” It is a weighting mechanism. It can be suggestive, but it is not a guarantee of explanation.
4) Next-token prediction: generating text one step at a time
Finally, the model generates by predicting the next token repeatedly until a response is produced. That objective is why the output can feel fluent and coherent. It is also why it can produce fluent text that is incorrect, ungrounded, or overly confident.
In the metaphor, it is like repeatedly selecting what to keep from each pass, one small choice at a time. Small choices compound.If you work with qualitative data, this part matters. Researchers already have sophisticated ways of working with text. Methods like content analysis, discourse analysis, and narrative analysis are not just different deliverables. They are different commitments about what text is, what counts as evidence, and what claims can be justified.
A literacy move is noticing that prompting can steer an LLM toward outputs that resemble different methodological stances.
For example, think of these three different questions and how you approach each of them:
- Content analysis often asks: what is being said, what categories appear, and how patterns show up across a dataset.
It tends to emphasize systematic coding and transparent decision rules.
- Discourse analysis asks: how is language doing social work, and how are power, identity, legitimacy, and agency constructed through linguistic choices.
It often emphasizes close attention to language in use and context.
- Narrative analysis asks: what story is being told, how events are sequenced, and how people make meaning over time.
It emphasizes temporality, turning points, and evaluation.
Exercise: Prompting as methodological steering
A prompt can function as a mini-analysis protocol. It sets, sometimes implicitly:
- unit of analysis (sentence, excerpt, full interview)
- analytic lens (coding, rhetorical features, narrative structure)
- output schema (codes, memo, story outline)
- evidence standard (what counts as support)
If you do not specify the evidence standard, the model will often provide confident interpretations that feel “researchy” but are hard to audit.
The context window: what the model can see becomes the dataset in the moment. What is inside the window might include:
- your instructions (the prompt)
- excerpts you paste
- chat history (in chatbot use)
- retrieved passages (in retrieval-augmented generation, or RAG)
This has a methodological implication. What you include in the window becomes the model’s effective corpus for that response. Everything outside the window is replaced by general patterns from training.
In the river metaphor, the context window is the stretch of river you can reach. Operational fluency is learning to pan quickly. AI literacy is remembering that you cannot find what is not within reach, and you should not pretend you did.
Chatbot vs RAG, two ways of building context:
- Chatbot mode: context is the conversation.
A common risk is drift over time, and loss of detail as earlier information gets pushed out of the window.
- RAG mode: context is your question plus retrieved chunks from a larger corpus.
The strength is that the response can be grounded in provided documents. A risk is retrieval bias, since what gets retrieved shapes what becomes salient and “true” in the moment.
Some principles and practices can help turn fluency into research-ready use, and the important thing here is treating the tool reflexively and making your process auditable.
- The Evidence Rule: For any analytic claim the model makes, require an exact quote from the excerpt(s) used and source ID
- Treat outputs as drafts at best, not findings: Think candidate codes, candidate memos, candidate interpretations.
- Stabilize your analytic protocol: Reuse the same instructions and schema across batches so results are comparable.
- Reflexive methodology: Think about the method you have for examining your
- Batch intentionally: Do not paste an entire dataset into a chat and hope for methodological miracles. Work in chunks, document decisions, then synthesize.
- Keep a lightweight audit log: Tool, date, purpose, key prompts, what you verified, what you rejected.
If you want a deeper dive into best practices from recent research on LLMs in research workflows, plus two short pieces I wrote that build on this workshop, you can find them here: Human in the Loop and Walled Garden.
Operational fluency can make you faster, which can also mean faster at making mistakes. Literacy enables you to make your use of LLMs meaningful enough to integrate into research in a way that aligns with methodologies, values, and evidence standards.
If you attended the AI literacy for research workshop (GCDI February 2026), thank you for the thoughtful discussion.
References and Suggested Reading:
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems.
Fairclough, N. (2003). Analysing discourse: Textual analysis for social research. Routledge.
Jain, S., & Wallace, B. C. (2019). Attention is not explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL).
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … Riedel, S. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Riessman, C. K. (1993). Narrative analysis. SAGE Publications. Information Processing Systems.
Stemler, S. (2001). An overview of content analysis. Practical Assessment, Research, and Evaluation, 7(1).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems.



 The final presenter was Roxanne Shirazi is associate professor and Head of Archives and Special Collections at the GC’s Mina Rees Library. Roxanne focussed her presentation on the
The final presenter was Roxanne Shirazi is associate professor and Head of Archives and Special Collections at the GC’s Mina Rees Library. Roxanne focussed her presentation on the